Banque publique de développement et acteur majeur du financement de l’économie française*, SFIL a choisi de concilier réponse règlementaire et efficacité opérationnelle en industrialisant ses backtestings.
*SFIL est le premier financeur du secteur public local et le premier apporteur de liquidités pour les grands contrats exports.
Depuis la crise financière de 2008, les réglementations et les autorités prudentielles exigent toujours plus de rigueur et d’attention dans la mise en place des mesures de vérification des processus de gestion des risques. Parmi ces mesures, figure le backtesting, un processus qui consiste à vérifier a posteriori les capacités de prédiction d’un modèle ou d’un dispositif de simulation. La Direction des Risques de SFIL assure ainsi le backtesting de 18 modèles de PD (Probability of Default) et LGD (Loss Given Default) utilisés pour la notation des clients et des transactions (octroi de crédit, calcul de fonds propres règlementaires…).
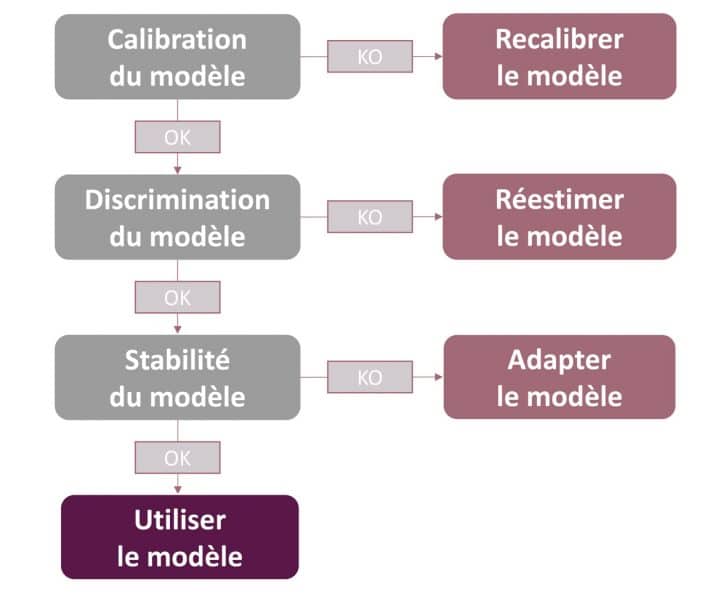
Conformément aux procédures internes définies par la banque et en accord avec les exigences règlementaires, la mise en œuvre opérationnelle d’un backtesting s’articule autour de l’analyse de trois critères :
La calibration : un système de notation interne est bien calibré si les taux de défaut constatés (réalité observée) n’excèdent pas significativement les probabilités de défaut calibré (prévision).
Le pouvoir de discrimination : il reflète la capacité à classer les clients de telle sorte que la proportion de clients qui font défaut augmente avec le classement du modèle (davantage de défauts observés pour les mauvaises notes).
La stabilité : elle permet de vérifier que les caractéristiques de la population concernée par un modèle ne changent pas significativement au fil du temps par rapport à la population de référence ayant servi à l’élaboration du modèle.
Il est important de souligner qu’outre l’exigence règlementaire de leur production annuelle, un plan d’actions doit être défini et suivi par la banque (voir le schéma ci-dessous).
Schéma 1 : plan d’action du backtesting
La solution
Fiabilité des process
Le défi opérationnel de la production des backtestings au sein d’une banque publique de développement en méthode avancée est d’être au rendez-vous des exigences réglementaires mais avec sobriété et efficacité. La production des backtestings, tout comme celle des paramètres bâlois du risque de crédit, requiert ainsi la mise en place de dispositifs semi-industrialisés voire industrialisés permettant de produire l’exercice à une fréquence au moins annuelle.
Une approche courante des banques consiste à développer un ensemble de programmes informatiques permettant de produire les résultats des indicateurs retenus par la banque à partir de l’ensemble des informations et des données d’un système de notation. Pour évaluer le niveau de calibration d’un modèle, il s’agit de réaliser des tests d’hypothèses statistiques allant de simples tests paramétriques et non paramétriques (1) de comparaison de moyennes d’échantillons (tests de Student, de Wilcoxon) à des tests plus complexes nécessitant des simulations de Monte Carlo en fonction de la nature des portefeuilles de la banque (test de Vasicek) (2). Ces différents tests et méthodes statistiques étant précisés et détaillés dans la littérature règlementaire, l’enjeu consiste donc à construire un dispositif fiable afin de les produire pour chaque modèle.
SFIL disposait jusque-là d’un environnement permettant de réaliser des backtestings unitaires selon un processus quasi-manuel, avec très peu d’industrialisation. Résultat : la production des indicateurs de performances prenait beaucoup de temps. Via son Pôle de Modélisation Quantitative, la Direction des risques de SFIL a souhaité disposer d’un environnement industrialisé permettant une production efficace et globale des backtestings.
(1) – Les tests paramétriques se fondent sur des distributions statistiques supposées dans les données, et ne sont donc valides que sous certaines hypothèses (normalité de distribution…) et adaptées à des échantillons d’une certaine taille ; sinon il faut avoir recours à des tests non paramétriques.
(2) – Le test de Student est un test paramétrique qui compare la probabilité observée d’une donnée à une probabilité théorique, ou à une valeur donnée.
Le test de Wilcoxon est un test non paramétrique pour comparer deux échantillons indépendants.
Le test de Vasicek est un modèle mathématiques qui décrit l’évolution des taux d’intérêt.
Le résultat
Une solution R pour industrialiser les backtestings
Avant le déploiement du projet, la majorité des traitements étaient réalisés en utilisant des programmes MATLAB (3), avec les contraintes que cela implique. La philosophie de MATLAB dans l’usage qui en était fait chez SFIL se prêtant peu à l’automatisation, de nombreuses tâches d’ajustement de paramètres étaient en effet réalisées « manuellement », lors de chaque backtesting.
Au-delà du coût des opérations, notamment de prétraitement des données, leur non-automatisation était par ailleurs source d’erreurs potentielles et obligeait à de très nombreux contrôles qui, dans une logique industrielle, peuvent être évités. D’un point de vue compétence enfin, l’expertise MATLAB est de plus en plus difficile à trouver, notamment sur des problématiques de type Data Science. Les nouveaux modes de production de backtestings devaient permettre de lever cette contrainte opérationnelle.
Après l’analyse d’une première chaîne représentative, deux grands principes ont été édictés pour mener à bien l’industrialisation des backtestings :
conserver les moteurs de calcul sous MATLAB afin de garantir la continuité de production entre les modèles existant et le backtestings. Ces codes étant également audités.
migrer les autres phases au profit d’une solution permettant une meilleure industrialisation : extraction des données ; prétraitements, ces étapes ayant été clairement identifiées comme prioritaires du fait d’un code complexe et de nombreux contrôles manuels ; génération de rapports.
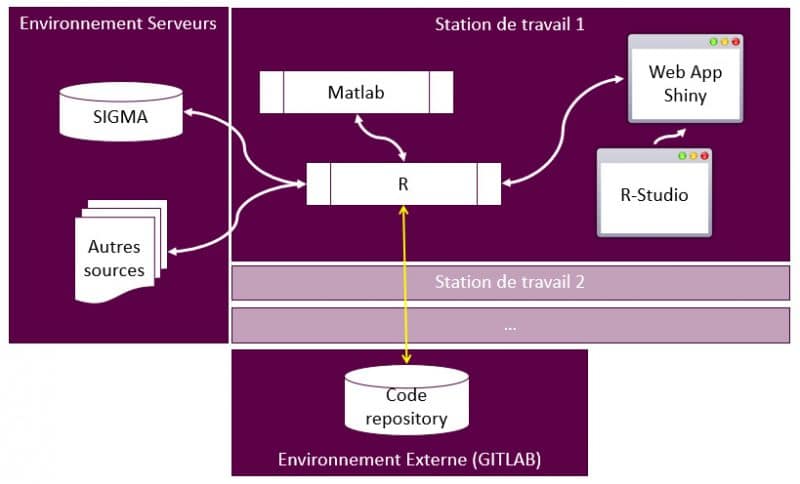
Les équipes de SFIL avaient déjà réalisé des développements avec R. Le langage de programmation et son logiciel libre associé ont donc naturellement été choisis. L’architecture cible pour industrialiser l’ensemble du processus a ensuite été définie selon le schéma ci-dessous, avec une suite de packages R indépendants et complémentaires. L’appel au cœur des calculs des backtestings, écrits en MATLAB, se fait directement depuis R, sans que l’utilisateur ait besoin d’interagir avec MATLAB.
Schéma 2 : Architecture cible du processus
Le transfert des compétences au centre du projet
Le développement de packages R et l’utilisation d’un gestionnaire de code ont constitué le principal défi technique de ce projet. Pour les équipes de SFIL, il y avait là une vraie opportunité pour monter en compétence en se formant à ces nouvelles techniques et méthodes. Pour rendre les équipes de SFIL complètement autonomes, le projet a été organisé de la façon suivante :
migration d’une première chaîne représentative, définition de l’architecture cible, et initialisation des packages R par les équipes de Datastorm ;
formation et accompagnement continus des équipes de SFIL, amenées à migrer les autres backtestings.
Point d’orgue de cette collaboration, une application web shiny a été développée pour permettre aux analystes de réaliser et de paramétrer aisément les différentes étapes nécessaires à la réalisation des backtestings… et cela, sans avoir à coder :
indicateurs de disponibilités des données et lancement des procédures SQL permettant d’extraire les tables sources ;
contrôle qualité et statistiques descriptives ;
paramétrisation et lancement des backtestings.
Pour la Direction des risques de SFIL, l’industrialisation des backtestings aura relevé d’une initiative à forte valeur ajoutée pour trois raisons :
tout d’abord une réduction significative du risque opérationnel grâce à l’uniformisation de l’exécution d’un backtesting dans toutes ses dimensions (constitution des données ; tests et analyses statistiques ; rapport).
Ensuite une démocratisation du profil du réalisateur : il n’est plus nécessaire d’être spécialiste du code pour réaliser un backtesting, ce qui apporte de la souplesse dans le staffing. L’accent a été mis sur l’uniformisation des sources de données ainsi que la normalisation du processus afin d’aboutir à un outil simple, ne nécessitant pas de connaissances techniques, et donc accessible à tous.
Enfin, une meilleure efficacité opérationnelle avec la réduction des coûts en ETP et en délais de réalisation. L’industrialisation va permettre aux équipes de se consacrer davantage aux travaux de modélisation, une telle amélioration concoure à mieux équilibrer le rapport Charge/Ressources.
Merci à : Idriss Alassane M Salla, Responsable de la Modélisation Quantitative, SFIL Julien Chambert, Analyste Quantitatif, Modélisation Quantitative SFIL Ismael Maiga Salifou, Analyste Quantitatif, Modélisation Quantitative SFIL Benoît Thieurmel, Directeur des opérations, Datastorm Lyès Boucherai et Martin Masson, Data Scientists, Datastorm
(3) – Système interactif de calcul numérique et de visualisation graphique
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.